Creación de un archivo pdf sin utilizar ni crystal report ni itextsharp, de esta manera no dependemos de dll engorrosas como Crystal Reports.
Liga de libreria: https://wkhtmltopdf.org/
Creación de un archivo pdf sin utilizar ni crystal report ni itextsharp, de esta manera no dependemos de dll engorrosas como Crystal Reports.
Liga de libreria: https://wkhtmltopdf.org/
Cuando comenzamos a utilizar Entity Framework vemos la maravilla de LINQ al obtener los datos de manera relacional, organizarlos como si de Sql se tratara, pero nunca nos preguntamos que de distinto tiene cuando utilizamos IQueryable o IEnumerable, para explicarlo rápidamente nos basaremos en la siguiente tabla (suponiendo que su nombre es tabla, literal):
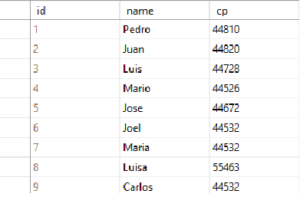
Cuando obtenemos los datos con IEnumerable de la siguiente forma:
IEnumerable<tabla> lst= from d in db.tabla
select d;
Si quisiéramos hacer un filtrado con una clausula where posterior a nuestra obtención de datos haríamos lo siguiente:
lst= lst.Where(d=>d.name=='Pedro');
Cuando utilizamos IEnumerable al llenar nuestro objeto con LINQ lo que obtenemos son los datos de la tabla en nuestra colección es decir, que al aplicar el filtrado trabajamos directamente con un conjunto de datos en memoria al cual se le hace el where directamente. Esto ocasiona un mal performance cuando nuestra tabla tiene millones de datos ya que los tendríamos en memoria y posterior aplicaríamos el filtrado, esto es una mala practica que jamas se debe hacer.
Ahora veamos la diferencia con IQueryable:
IQueryable<tabla> lst= from d in db.tabla
select d;
//lo que obtiene IQueryable despues de la consulta es:
// select * from tabla
Ahora haremos el mismo filtro posterior a la consulta:
lst= lst.Where(d=>d.name=='Pedro'); //y aquí lo que hacemos es concatenarle: select * from tabla where name='Pedro'
A diferencia de IEnumerable lo que tenemos en nuestro objeto IQueryable es la consulta SQL en sí, es decir tenemos algo como lo siguiente:
select * from tabla where name='Pedro'
En conclusión si vamos a realizar filtrados dinámicos en un conjunto de datos se debe utilizar la interface IQueryable, es la forma correcta de aplicar manipulación a nuestra consulta antes de enviarla al servidor de base de datos. ¿Cuando se realizar el envió de la consulta al servidor por parte de IQueryable? Cuando hacemos uso de los datos es decir, cuando aplicamos un foreach o hacemos un ToList().
Para poder cachar excepciones dentro de una consulta LINQ y poder manipular el error para que no truene la consulta en si misma debemos hacer uso de Lambda, esto es útil cuando nuestra base de datos puede presentar inconsistencias las cuales pueden ocasionar una excepción en ciertos casos, y podemos evitarlo de la siguiente forma:
EntityDB db= new EntityDB();
var lst = from d in db.tabla.ToList() //es importante hacerlo lista
select new TablaViewModel
{
id = d.id,
//campo es string por lo cual
//nuestra función delegada regresara igual string
campo = (new Func<string>(() => {
try {
// suponiendo que exista una referencia
// a una tabla secundaria la cual no siempre exista
// lo cual puede ocasionar una excepción
// de esta manera lo podemos manipular
return d.tablaSecundaria.campo2;
}
catch { return "No existe"; }
}
)
)()
};
De esta manera nuestra consulta no tronara y podemos darle un resultado a la vista donde mostraremos nuestros datos.
¿Cual es la diferencia de utilizar o no utilizar indices en nuestras tablas? Experimento con unas consultas para ver el rendimiento de utilizarlos y no utilizarlos:
Esta entrada fue impresa en el número publicado en Marzo 2018 de la revista Talento Empresarial.
Mi experiencia con facturación electrónica viene desde el desarrollo de la plataforma www.facturacenter.com.mx, posterior a ese desarrollo he hecho miles más que van desde servicios web, consultoría a empresas y algunos municipios del país, y lo último la migración de cfdi 3.2 a 3.3 de algunos sistemas.
Tratare de dar mi punto de vista como desarrollador de software, no soy experto en contabilidad ni temas fiscales, yo solo soy un desarrollador de software por lo cual puedo desconocer algunos temas a la perfección. En esta entrada me enfocare en la adaptación de los usuarios a este mecanismo.
Entiendo las ventajas que significan para SAT que los contribuyentes emitan facturas electrónicas, ya que esto da mayor control a todo movimiento que hacen las pequeñas y grandes empresas, y poco a poco quitando el trabajo de los contadores de calculadora, y todo electrónico sin gastar papel, ni renovar los folios y todo el engorro que se hacía hace años. Lo malo del asunto es haber optado por sacar una versión 3.2 con tanta deficiencia la cual quieren tapar con la nueva versión 3.3 (la cual creo que complica todo al contribuyente, ahorita vamos para allá). No sé a quién consulto SAT para realizar la facturación electrónica en cuanto a sus secciones y formatos, catálogos, atributos, complementos etc. Hay características buenas como todo, pero las deficiencias que tenía la versión 3.2 quisieron mejorarlas teniendo un mayor control en lo que captura el contribuyente, cambiándolo todo (o casi todo) a claves, esto asegurando que el emisor no captura discrepancias, todo suena perfecto y como programador lo aplaudo, pero esto debió ser parte de la versión 3.2 no de la 3.3. ¿Qué es lo que pasa ahora con todo el tema de la migración? Que todos los sistemas fueron hechos para la versión 3.2 una versión que fue perfeccionándose y si la comparamos con la versión 3.3 hace un caos en los sistemas y en los usuarios que utilizan dichos sistemas.
Un usuario que estaba acostumbrado: 10,20 quizá 30 o más años a hacer sus facturas con papel se le obliga a realizar facturación electrónica, ya que no fue opcional sino obligatoria al final, esta persona nunca ha utilizado una computadora, meses después el usuario comienza a crear su factura, y de repente le toca un cliente al cual le obliga hacer una addenda, el usuario no tiene ni idea que es una addenda, lo peor aún, el sistema que utiliza el usuario no tiene dicha addenda(si porque cada receptor puede hacer su addenda), el usuario llama a su proveedor de software y le dicen que la addenda estará lista en unos días. Por fin llega el día y el usuario ve que para hacer una factura para ese cliente en particular (ya que si la factura está mal no recibe su pago) debe llenar más datos y cuando por fin logra hacer la factura, se encuentra con una nueva sorpresa, el cliente le dice que la factura debe subirse a una página web la cual validara la addenda, y al subirla el sitio del cliente le dice que su factura no es válida; la persona nuevamente llama a su proveedor de software y se vuelve un ciclo prueba y error hasta que resuelve una problemática que no tenía cuando solo utilizaba papel. Este es un pequeño ejemplo de la problemática que pasó un contribuyente al migrar de papel a facturación electrónica. ¿Sera verdad que con la facturación electrónica se beneficia el contribuyente? O ¿Quién se beneficia realmente? El contribuyente en lugar de beneficiarse ha gastado en un software caro y en más tiempo del que utilizaba para hacer algo que hacía en minutos.
Después de 6 años cuando los contribuyentes por fin llevan una vida más o menos tranquila en cuestión de facturación (a veces falla el pac, se caducaron sus sellos), y sale la súper noticia de la migración a la nueva súper poderosa facturación electrónica 3.3 la cual contiene miles de mejoras, más organizada, lo mejor que le pudo pasar al contribuyente, y arrojan como 20 catálogos los cuales deben ser utilizados ahora en lugar de que el usuario capture lo que siempre capturaba. Ahora para capturar conceptos el SAT obliga a que capture el usuario el producto y una clave que proporciona el bondadoso SAT, y lo dicen como si el usuario solo buscara la clave entre más de 50 mil (un numero absurdo y más adelante veremos porque) y rápidamente le resolviera su vida pero aquí es por lo cual dije con anterioridad, estos catálogos debieron salir en la anterior versión, las personas ya utilizan sistemas donde tienen hasta miles de productos, los contribuyentes viven al día, y ahora para hacer una factura deben ir producto por producto buscando la clave más o menos adecuada (ya que hay ambigüedades) esto en el caso de los conceptos, ah pero si te equivocas el SAT te dará perdón unos meses porque los contribuyentes son unos pecadores por no saber cuál es la clave de sus conceptos. Ahora veamos lo absurdo de este famoso catalogo:
Estos son unos ejemplos, y es cuando me pregunto ¿En realidad eran necesarios más de 50 mil elementos? Además esto está lleno de huecos, hay bastantes ambigüedades, y otro problema es que ese catálogo debe seguir creciendo a la lógica del SAT, ya que habrá cada vez nuevos productos, creo que si querían absorber todo producto posible se metieron en un problema enorme. Se debió contemplar una categorización menor, no más de 1000 elementos, esto ayudaría bastante al usuario, pero yo casi estoy seguro que este catálogo tiende al fracaso. El simple hecho de evaluar si corresponde lo que capturo el cliente con la clave ya es algo engorroso, así que no dudo que el siguiente año se elimine o se reduzca este catálogo así como el de unidad que también es otra maravilla.
Hablar de facturación electrónica es un tema para más de una entrada, es por ello que me enfoque en la adaptación en estos años, en otras entradas hablare de los monopolios existentes, nomina electrónica, y también del famoso y paradójico complemento de pago.
La facturación electrónica también tiene sus puntos buenos y puede mejorar la forma en como está organizada, lástima que SAT teniendo recaudaciones enormes (2015: 300 mil millones de pesos) no invierta ni el 1% de eso para su departamento de sistemas (siguen utilizando applets, yo amo java, no las applets).
Nos vemos en siguientes entradas.
Algunas veces tenemos la necesidad de conectarnos a un proyecto que está en desarrollo, es decir está programándose aun y se encuentra en una solución de visual studio, ya sea para probar una aplicación móvil conectándose al servicio web o para conectarnos desde un celular y ver como se verá un sitio web responsivo.
Los pasos son los siguientes, todos son sobre el equipo que tiene el código fuente:
<site name="MiProyecto" id="1">
<application path="/" applicationPool="Clr4IntegratedAppPool">
<virtualDirectory path="/" physicalPath="C:\Users\User\Documents\MiProyecto\MiProyecto" />
</application>
<bindings>
<binding protocol="http" bindingInformation="*:2248:localhost" /><span data-mce-type="bookmark" style="display: inline-block; width: 0px; overflow: hidden; line-height: 0;" class="mce_SELRES_start"></span>
</bindings>
</site>
<site name="MiProyecto" id="1">
<application path="/" applicationPool="Clr4IntegratedAppPool">
<virtualDirectory path="/" physicalPath="C:\Users\User\Documents\MiProyecto\MiProyecto" />
</application>
<bindings>
<binding protocol="http" bindingInformation="*:2248:localhost" />
<binding protocol="http" bindingInformation="192.168.0.26:2248:*" />
</bindings>
</site>
Con eso bastara para que puedan conectarse de otro equipo a la maquina que tiene el desarrollo, sin importar que el otro equipo esa movil, mac o pc, e igual podrá debuggearse el código.
Hace poco me toco modificar un proyecto que tenía sin modificarlo algunos años, mi sorpresa fue que al modificar el DataSet se destruyó y todos sus métodos, TableAdapters etc me marcaba como si fueran ambiguos o inexistentes. Después de unas horas sufriendo logre corregirlo de la siguiente manera:
Y listo con esos pasos se restablecerá el DataSet.
Este es un tema muy subjetivo pero el cual es tan importante como el conocer el lenguaje de programación y herramientas de terceros.
La abstracción es un concepto filosófico que comenzó por las reflexiones filosóficas de aquel pensador llamado Aristóteles (dudo que hubiera sido el primero), y se resume como las propiedades y funciones que hacen un objeto (esos griegos ya sabían POO). En palabras simples, la abstracción es aquello que hace que un triángulo no sea un cuadrado, y si un sujeto entiende un triángulo a la perfección y otro sujeto también lo entiende a la perfección deberían ver el concepto de triángulo de la misma forma. Claro esto es yéndonos al extremo de abstracción.
¿Entonces todas estas cosas marihuanas a que nos llevan o para que nos sirven en la programación? Pues sirve prácticamente para trabajar menos.
Los requerimientos son los que definen un problema y para resolver ese problema es para lo que nos pagan, cuando tenemos un par de años trabajando desarrollando software es más fácil identificar los requerimientos parecidos y por lo cual es más fácil aplicar funcionalidades compartidas, en sí, estamos aplicando abstracción funcional al desarrollo, por lo cual trabajaremos menos pero pensaremos más (cuando digo más no hablo de tiempo aplicado sino de complejidad).
Un poco de abstracción no hace daño, un poco de herencia, sobrecarga y rehusó de funcionalidad ayuda a crear más estética en nuestro código, pero como todo, el exceso es malo, el balance de cuanta abstracción utilizar es decisión de uno, y cuando hablo de saber cuánto rehusó de funcionalidad utilizar, hablo por los cambios de requerimientos que a veces van desde una funcionalidad única en solo un módulo la cual nos hace re-codificar mucho.
Como conclusión, la abstracción es algo que se aprende por uno mismo con la experiencia, ni un curso ayudara a tener mejor abstracción, ni gurus, ni evangelistas, lo único que nos hará mejorar el nivel son los distintos problemas nacidos de distintos requerimientos.
Para esto necesitaremos crear la función mítica Split de sql que tiene años en internet y pongo a continuación (desconozco el autor):
CREATE FUNCTION [dbo].[fn_Split](@text varchar(8000), @delimiter varchar(20) = ' ')
RETURNS @Strings TABLE
(
position int IDENTITY PRIMARY KEY,
value varchar(8000)
)
AS
BEGIN
DECLARE @index int
SET @index = -1
WHILE (LEN(@text) > 0)
BEGIN
SET @index = CHARINDEX(@delimiter , @text)
IF (@index = 0) AND (LEN(@text) > 0)
BEGIN
INSERT INTO @Strings VALUES (@text)
BREAK
END
IF (@index > 1)
BEGIN
INSERT INTO @Strings VALUES (LEFT(@text, @index - 1))
SET @text = RIGHT(@text, (LEN(@text) - @index))
END
ELSE
SET @text = RIGHT(@text, (LEN(@text) - @index))
END
RETURN
END
Una vez con la función Split agregada a nuestra base de datos de la siguiente manera podemos aplicar una cadena que contenga ids y aplicarles alguna modificación a los registros dentro dicha cadena, por ejemplo una procedimiento que modifique un campo(o varios) en común de varios registros recibiendo una cadena con los ids:
CREATE FUNCTION [dbo].[fn_Split](@text varchar(8000), @delimiter varchar(20) = ' ')
RETURNS @Strings TABLE
(
position int IDENTITY PRIMARY KEY,
value varchar(8000)
)
AS
BEGIN
DECLARE @index int
SET @index = -1
WHILE (LEN(@text) > 0)
BEGIN
SET @index = CHARINDEX(@delimiter , @text)
IF (@index = 0) AND (LEN(@text) > 0)
BEGIN
INSERT INTO @Strings VALUES (@text)
BREAK
END
IF (@index > 1)
BEGIN
INSERT INTO @Strings VALUES (LEFT(@text, @index - 1))
SET @text = RIGHT(@text, (LEN(@text) - @index))
END
ELSE
SET @text = RIGHT(@text, (LEN(@text) - @index))
END
RETURN
END
Y así la mandaríamos llamar:
EXEC sp_algo '1,3,5,7,77,65,666','leviathan'
Esto es útil y rápido cuando se desea modificar masivamente una colección de registros (por ejemplo desde un backend con entity framework) los cuales tendrán el mismo valor en uno de sus campos, solo tomar precauciones con SQL INJECTION (es 2017 y si aún existe)
En c# existe una manera fácil para recorrer dinámicamente los atributos de un objeto, de la siguiente manera podemos obtener el valor de un objeto dinámicamente y también el nombre de sus atributos en forma de cadena, para ello haremos uso de la clase PropertyInfo con la cual podemos obtener la estructura de nuestro objeto, abajo comento y pongo un ejemplo simple para entenderlo:
Clase para el ejemplo:
public class Auto
{
public string Nombre { get; set; }
public string Marca { get; set; }
public string Modelo { get; set; }
public int Año { get; set; }
}
Y para realizar el recorrido de los atributos lo hacemos de la siguiente manera:
Auto oAuto = new Auto() { Nombre = "Mi auto", Marca = "Honda", Modelo = "Civic", Año = 2018 };
PropertyInfo[] properties = typeof(Auto).GetProperties();
foreach (PropertyInfo property in properties)
{
//así obtenemos el nombre del atributo
string NombreAtributo=property.Name;
//así obtenemos el valor del atributo
string Valor=property.GetValue(oAuto);
Console.WriteLine("El atributo "+NombreAtributo+" tiene el valor: "+ Valor);
}
Y el resultado:
El atributo Nombre tiene el valor: Mi auto
El atributo Marca tiene el valor: Honda
El atributo Modelo tiene el valor: Civic
El atributo Año tiene el valor: 2018
Si agregamos nuevos atributos a nuestra clase este algoritmo seguiría recorriendo dinámicamente todas la nuevas propiedades de nuestra clase.